About the Grid¶
In this page you will find some general information about the Grid, how it works and what is suited for:
Introduction to Grid¶
The Grid is a loosely coupled collection of heterogeneous resources with a large variety in purpose and reliability. The Grid consists of multiple geographically distributed compute clusters interconnected with fast network. Grid computing is different from conventional high performance computing such as cluster computing in that Grid systems typically have each processor core perform an independent task.
In addition, Grid clusters are not exclusively connected to their own storage facilities but can be accessed transparently from all Grid compute clusters, and as such form a virtual supercluster. Grid systems and their applications are more scalable than classic clusters.
The Grid is especially suited, therefore, to applications that cannot be solved in a single cluster within a reasonable timeframe. Common examples are the Large Hadron Collider (LHC) experiments, large-scale DNA analyses and Monte-Carlo simulations.
To use the Grid or not¶
Grid computing is a form of distributed computing which can be very powerful when applied correctly. Grid is best suited for applications with a data-parallel nature that require many simultaneous independent jobs. With the help of the Grid, large scale computational problems can be solved and large amounts of data can be handled and stored.
Note
The Grid suits applications that can be split up relatively easily in multiple, independent parts or else embarrassingly parallel jobs.
Job submission has a relatively high overhead. Submitting a “hello world” program may take minutes. Your data and your software must be available on the worker nodes, which requires careful planning of the job workflow. With the size of the job collections typical for the Grid, and submitting hundreds or even thousands jobs simultaneously, it may become a challenge to check your jobs for status and reschedule based on judgement of failures and their causes. We offer tools to help you automate these actions (see Pilot jobs), however, porting of your solution to the Grid will always require time and effort to set up. Our experienced consultants are available for assistance and to help you make the right decisions right from the beginning.
The Grid infrastructure is able to accommodate a variety of communities and scientific fields, each with their own type of application and requirements, and without mutual interference. Typical Grid applications are:
Massive data processing workloads.
Large computational job collections that require a minimal time to completion.
Projects that require collaboration and resource sharing with national or international partners.
How it works¶
As a user you connect to the Grid by connecting to a so-called User Interface (UI) system via secure shell. Once you have received the right credentials for a UI (see Preparation) you are set to go.
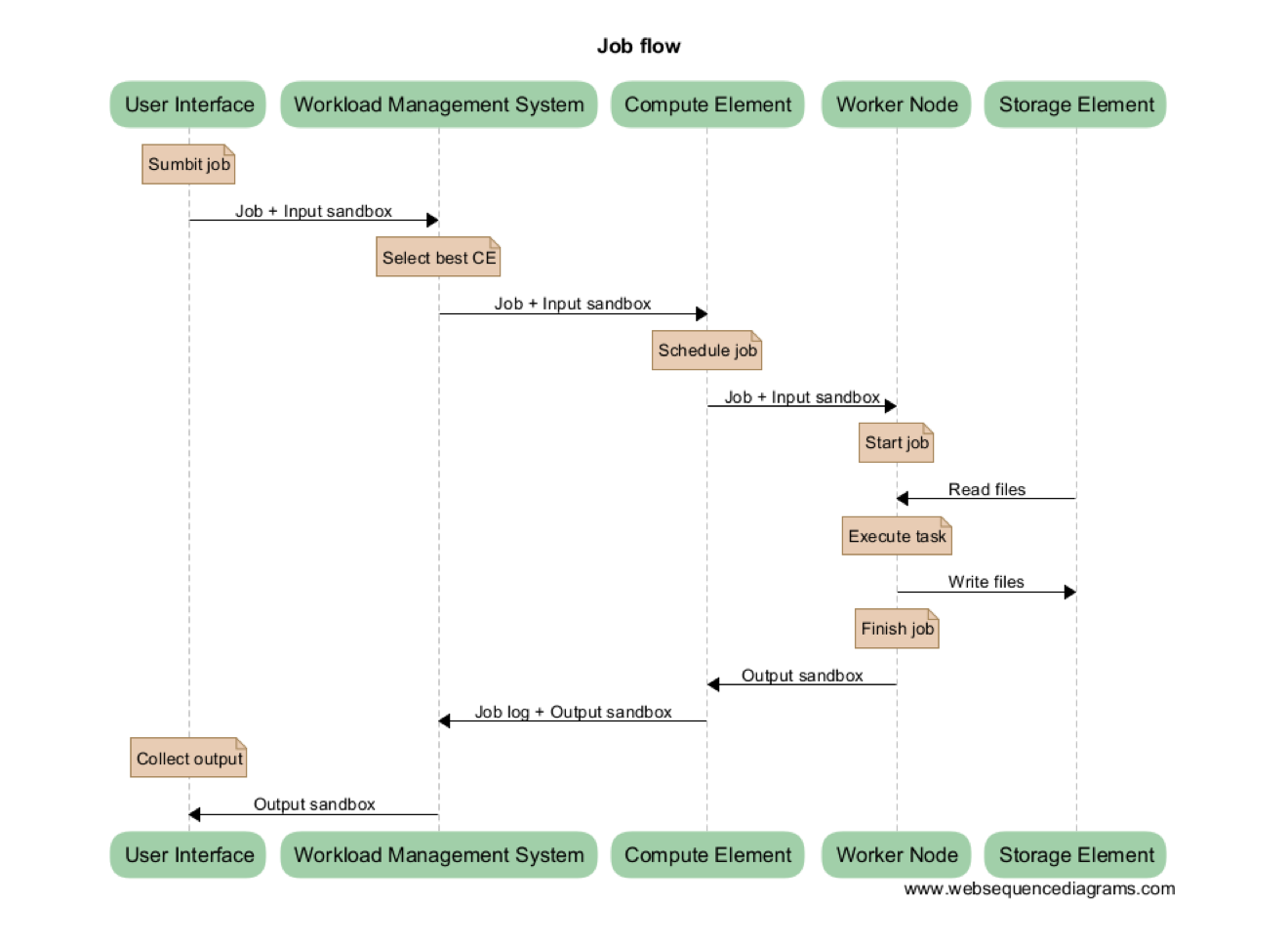
In general your task needs to be split into smaller units, called jobs, that each fit a certain set of boundary conditions in terms of resources (typically runtime, memory, disk size). For the jobs to be executed on the Grid, a job slot needs to be selected based on the boundary conditions that suit the requirements for these jobs. The way to do this is to describe each job in terms of a Job Description Language (JDL), where you list which program should be executed and the requirements of the job slot to run the job. You can use the input and output sandboxes to send small data files or scripts with your job.
Each job is then submitted as a JDL file to the Workload Management System (WMS). The WMS is a resource broker that knows which Grid compute clusters are ready to accept your job and fulfil its requirements. Each Grid cluster consists of a Compute Element (CE) and several Worker Nodes (WNs). The CE is a scheduler within each Grid cluster that communicates with the WMS about availability of the job slots in the cluster, and accepts and distributes the jobs to the available compute nodes in the cluster (these are called Worker Nodes or WNs). These WNs are the machines which do the actual work. When finished with a job they will report back to the CE, which in turn will inform the WMS about the status of the job.
In addition, the Grid’s interconnected clusters each have a storage server, called a Storage Element (SE), which can hold the input and output data of the jobs. Data on the SEs can be replicated at multiple sites if needed for scale-out scenarios. In general, all SEs offer disk storage for the staging of datasets before and after job execution. In addition, a central Grid storage facility (see dCache) also provides tape storage for long-term storage of datasets that need to be preserved.
In short, as a user you submit your jobs to execute your calculation or analysis code and to handle your input and output data. The WMS distributes the jobs to the clusters and node that are most suitable for these jobs. When the jobs are finished, you can collect the results from the SE that was selected to hold the output data or keep them for later use on the central Grid storage facility.