
Grid storage¶
In this page we will talk about the Grid storage facilities, the tools to interact with it and the method to handle data that is stored on tape.
About Grid storage¶
Each cluster on the Grid is equipped with a Storage Element or SE where data is stored. The Grid storage is useful for applications that handle large amount of data that can not be sent with the job Sandbox or stored in a pilot job database.
You can interact with the Grid storage from the UI or from a Worker Node, within your running job. The scripts that can access the Grid storage can be submitted from:
To use the Grid storage you must:
Be member of a VO for which we have allocated storage space.
You can access the Grid storage with Grid Storage clients, through interfaces that speak protocols like GridFTP, GSIdCap or Webdav (deprecated: SRM). With these storage clients you can:
list directories and files
read (download) files
write (upload) files
delete files or directories
stage files (copy them from tape to disk for faster reading)
dCache¶
The storage element located at SURFsara is accessible from any Grid cluster or UI. It uses the dCache system for storing and retrieving huge amounts of data, distributed among a large number of server nodes. It consists of magnetic tape storage and hard disk storage and both are addressed by a common file system. See dCache specifications for details about our dCache instance.
Grid file identifiers¶
You can refer to your files on the Grid with different ways depending on which of the available Storage clients you use to manage your files:
Transport URL or TURL¶
Examples:
# lsgrid user homer stores the file zap.tar on dCache storage
gsiftp://gridftp.grid.surfsara.nl:2811/pnfs/grid.sara.nl/data/lsgrid/homer/zap.tar
# same, but with a Webdav TURL
https://webdav.grid.surfsara.nl/pnfs/grid.sara.nl/data/lsgrid/homer/zap.tar
Storage URL or SURL¶
Example:
# lsgrid user homer stores the file zap.tar on dCache storage
srm://srm.grid.sara.nl:8443/pnfs/grid.sara.nl/data/lsgrid/homer/zap.tar
Default ports¶
Protocol |
Host(s) and port(s) |
Remark |
|---|---|---|
SRM (deprecated) |
srm://srm.grid.sara.nl:8443 |
Protocol is DEPRECATED |
GridFTP |
gsiftp://gridftp.grid.surfsara.nl:2811 |
Data channel port range: 20000-25000 |
Webdav |
See webdav clients for details |
|
xroot |
xrootd.grid.surfsara.nl:1094 |
Used by CERN only |
all |
ipv4.grid.surfsara.nl |
For clients that don’t speak IPv6 |
dCacheView |
User-friendly web interface |
|
API |
Application programming interface |
ipv4.grid.surfsara.nl is a single VM that supports only IPv4 and no IPv6. It can be used for small scale access through GridFTP, Webdav or Xroot where IPv6 causes problems. Don’t use it for batch processing.
https://dcacheview.grid.surfsara.nl is a landing page that shows all flavors of dCacheView and API. Visit the page to see the port numbers.
Storage clients¶
The InputSandbox and OutputSandbox attributes in the JDL file are the basic way to move files to and from the User Interface (UI) and the Worker Node (WN). However, when you have large files (from about 100 MB and larger) then you should not use these sandboxes to move data around. Instead you should use the dCache and work with several Storage clients.
In this section we will show the common commands to use the various storage clients.
Note
From the many Grid storage clients, we recommend you to use the : globus client or gfal client. These tools have a clean interface, and their speed is much better on our systems compared with their srm-* equivalents.
Staging files¶
The dCache storage at SURFsara consists of magnetic tape storage and hard disk storage. If your quota allocation includes tape storage, then the data stored on magnetic tape has to be copied to a hard drive before it can be used. This action is called Staging files or ‘bringing a file online’.
Note
Staging is important. If your job reads a file that is on tape but not online, your job will wait until dCache brings the file online (or reaches a timeout). This may take minutes when it’s quiet, but it may take days when multiple users are staging large datasets. That would be a waste of CPU cycles. But that’s not all: the number of concurrent transfers is limited per pool, so it would also be a waste of transfers slots.
Locality |
Meaning |
|---|---|
ONLINE |
The file is only on disk |
NEARLINE |
The file is only on tape; it should be staged before reading it |
ONLINE_AND_NEARLINE |
The file is both on disk and on tape |
There are some more file statuses. See the SRMv2 specifications for a full list, note that SRM is deprecated.
The Grid storage files remain online as long as there is free space on the disk pools. When a pool group is full (maximum of assigned quota on staging area) and free space is needed, dCache will purge the least recently used cached files. The tape replica will remain on tape.
The amount of time that a file is requested to stay on disk is called pin lifetime. The file will not be purged until
the pin lifetime has expired.
There are different ways to stage your files on dCache. For running the staging commands, it is required to authenticate to dCache either with a valid proxy certificate or username/password or a macaroon depending on the client. We support the following clients:
gfal2 supported by CERN. It allows proxy authentication only.
ada supported by SURF. It allows proxy or username/password or macaroon authentication.
srmbringonline. It supports proxy authentication only.
The preferred method for bulk staging is the gfal2 practice below.
gfal2 python API¶
The gfal2 API provides a set of functions to support staging operations. Given a SURL or TURL list of files, the following gfal2 scripts can be used:
state.py: display the locality (state) of the files
stage.py: stage (bring online) the files and return a token
release.py: release the files based on the token
The following section gives an example of usage of the gfal2 scripts.
Preparation¶
Download the scripts on the UI and inspect the usage instructions inside each of state.py, stage.py, release.py.
Create a file that includes a list with SURLS (srm://srm.grid.sara.nl/..) of the files you want to stage from tape, e.g. the file called mysurls inside the folder datasets:
$cat datasets/mysurls
#srm://srm.grid.sara.nl/pnfs/grid.sara.nl/data/lsgrid/homer/file1
#srm://srm.grid.sara.nl/pnfs/grid.sara.nl/data/lsgrid/homer/file2
#srm://srm.grid.sara.nl/pnfs/grid.sara.nl/data/lsgrid/homer/file3
In case that you plan to stage a big bulk of data, split the filelist in chunks of 1000 files:
$split -l 1000 --numeric-suffixes [datasets/mysurls] [output_prefix]
State operations¶
Check the state of the files with:
$python state.py --file [datasets/mysurls]
#srm://srm.grid.sara.nl/pnfs/grid.sara.nl/data/lsgrid/homer/file1 ONLINE_AND_NEARLINE
#srm://srm.grid.sara.nl/pnfs/grid.sara.nl/data/lsgrid/homer/file2 NEARLINE
#srm://srm.grid.sara.nl/pnfs/grid.sara.nl/data/lsgrid/homer/file3 NEARLINE
If your surls filelist is too long it is better to redirect the output of this command in a file.
Display the total number of files on tape and/or disk:
$python state.py --file [datasets/mysurls] | awk '{print $2}' | sort | uniq --count
#1 ONLINE_AND_NEARLINE
#2 NEARLINE
If your surls filelist is too long, please use the token returned by the stage.py (see section below) to retrieve the state of your files. It improves performance significantly! Given a token id [5d43ee2e:-1992583391] the equivalent commands would be:
$python state.py --file [datasets/mysurls] --token [5d43ee2e:-1992583391]
$python state.py --file [datasets/mysurls] --token [5d43ee2e:-1992583391] | awk '{print $2}' | sort | uniq --count
Stage operations¶
Submit a staging request for your surls filelist. The command returns a token that you can use to check the state of the files:
$python stage.py --file [datasets/mysurls]
#Got token 5d43ee2e:-1992583391
You can store the output in a file stage.log to make sure that you keep safe the token IDs of your stage requests. This is required to state/release the files later on.
Note
The token always corresponds to the given surls file list. You need to use the exact same surls file in your state/release commands. If you add/remove any file in your surls filelist and use the old token, you will get an error.
Note
In case that you plan to stage a big bulk of data, then submit each chunk of 1000 files with 1 minute interval time to prevent overloading the staging namespace server.
The pin lifetime is set in seconds, the default pin time in the script is set to two weeks (or 1209600 sec). You can request the desired pin time with the argument [–pintime pintime]:
$python stage.py --file [datasets/mysurls] --pintime [pintime in seconds]
#Got token 5d43ee2e:-1992583393
The pin lifetime counts from the moment you submit the request independent to the actual time that the files are on disk.
Unpinning operations¶
Release the pin of your bulk of files with:
$python release.py --file [datasets/mysurls] --token [5d43ee2e:-1992583391]
After submitting the unpinning command above, the files will remain cached but purgeable until new requests will claim the available space.
If your surls filelist is too long it is better to redirect the output of this command in a file.
Monitor staging activity¶
Once you submit your stage requests, you can use the gfal scripts to monitor the status or check the webpage below that lists all the current staging requests:
Unpin a file¶
The disk pool where your files are staged has limited capacity and is only meant for data that a user wants to process.
When you stage a file you set a pin lifetime. The pin lifetime here is set to 1 week, but note that this counts from
the moment you submit the request independent to the actual time that the files are on disk. The file will not be purged
until the pin lifetime has expired. Then the data may be purged from disk, as soon as the space is required for new stage
requests. When the disk copy has been purged, it has to be staged again in order to be processed on a Worker Node.
When a pool group is full with pinned files, staging is paused. Stage requests will just wait until pin lifetimes for other files expire. dCache will then use the released space to stage more files until the pool group is full again. When this takes too long, stage requests will time out. So pinning should be used moderately.
When you are done with your processing, we recommend you release (or unpin) all the files that you don’t need any more. It is an optional action, but helps a lot with the effective system usage.
Release the pin of your bulk of files with:
$python release.py --file [datasets/mysurls] --token [5d43ee2e:-1992583391]
This command will initiate unpinning of files in mysulrs list. If your surls filelist is too long it is better to redirect the output of this command in a file.
Warning
At the moment neither the srm-bring-online nor the python gfal release.py scripts can effectively release a file if there are multiple pin requests. Please use srm-release-files if you want to release all the pins set to a file.
Checksums¶
dCache checks the checksum of a file on many operations (for instance, during tape store & restore operations). If dCache finds, that the checksum of a file does not match the checksum it has in its database, dCache will refuse to continue and will present an error message instead.
dCache is configured to use Adler32 checksums by default, for performance reasons. It is however possible to transfer files to dCache while verifying MD5 checksums. Globus Online works only with MD5 checksums, and previous versions of dCache did not support MD5 checksums, so one would have to disable checksum checking in Globus. Now, dCache does support MD5 checksums during transfers, even when the default checksum type is Adler32. So now Globus Online and dCache should be able to work together with checksums enabled. If a GridFTP client uploads data with MD5 verification enabled, dCache will calculate the MD5 checksum, return this to the client and store it in its database.
dCache does not enable a user to add MD5 checksums of existing data.
We may however, if your project needs it, change the default checksum from Adler32 to MD5 for your poolgroups. From the moment we do that, for new files, dCache will store MD5 checksums in its database, and this MD5 checksum will be used to verify file integrity during operations. For existing data, we can tell dCache to calculate the new checksums. Tape data will have to be staged to do this. MD5 checksums require more CPU than Adler32, so there will be a performance impact for writing, staging and reading data.
Checksums can be listed with srmls -l:
$srmls -l srm://srm.grid.sara.nl/pnfs/grid.sara.nl/data/lsgrid/test | grep locality
Also through webdav clients and gfal client you can retrieve a file’s checksum. The checksum value comes from the database so it performs well.
Transport security¶
With most protocols, the authentication is done over a secured channel (usually encrypted with TLS). After authentication, the data is transferred in plain text. Since most users are from High Energy Physics, this is usually no problem.
Life scientists however may need to store private data such as MRI scans or DNA scans. The European GDPR law requires careful handling of such personal data. We therefore suggest that you keep such data safe during transport. Below we give an overview which protocols in dCache encrypt data during transfer.
Data channel encryption:
WebDAV over port 2880, 2881, 2883 and 2884 (we configured 2881 and 2884 to have the most secure encryption)
WebDAV over port 443 only through https://webdav-cert.grid.sara.nl
NO data channel encryption:
WebDAV over port 443
WebDAV over port 2882
SRM - deprecated
GridFTP (dCache does not support GridFTP data encryption. Please be warned that
globus-url-copy -dcprivdoes not warn you about this and transfers your data in plain text.)GSIdCap, dCap
Xroot
Since WebDAV is currently the only way to encrypt data in transit, we continuously try to improve the security of our WebDAV doors. We regularly test our WebDAV doors with tools like the Qualys SSLtest, nmap, Greenbone/OpenVAS, and others, and follow their recommendations.
The conclusion: if your data is personal, safely upload it to and download it from dCache, by using WebDAV over ports 2881 or 2884. See webdav clients for more information.
SRM interaction example diagram¶
Note: SRM is deprecated.
Here is a sequence diagram that illustrates how the SRM commands interact with the Grid storage.
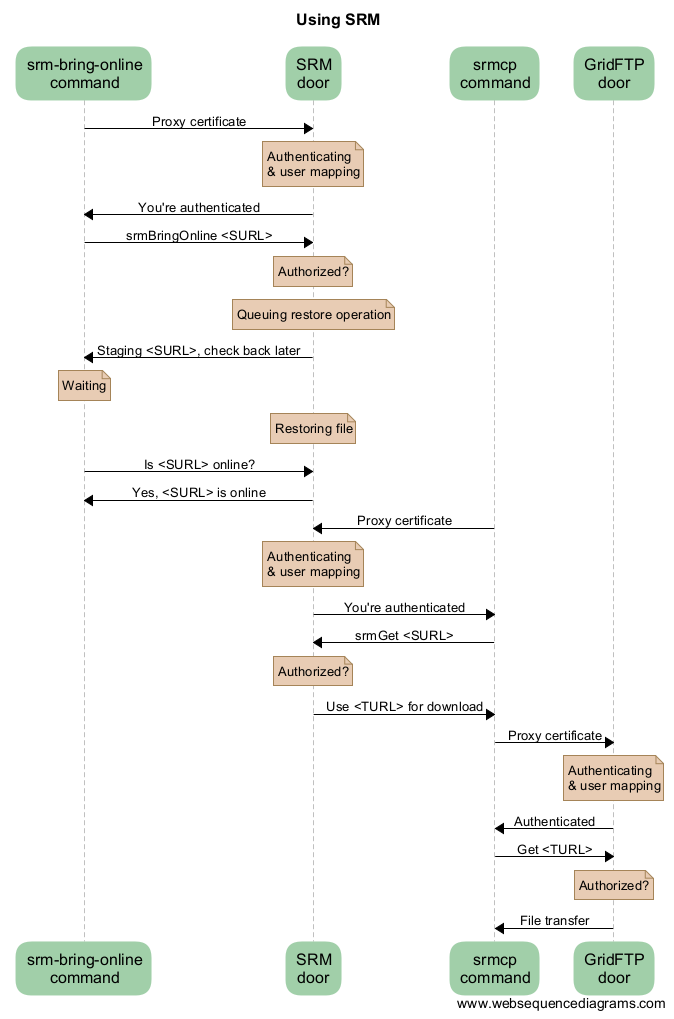
As you can see from this diagram, there can be a lot of overhead per file. For this reason, Grid storage performs best with large files. We recommend to store files of several megabytes to gigabytes. Some users have files of more than 2 terabytes, but that may be impractical on other systems with limited space like worker nodes.
Importing large amounts of data¶
The Data Ingest Service is a SURFsara service for researchers who want to store or analyse large amounts of data at SURFsara. The service is convenient for users who lack sufficient bandwidth or who have stored their data on a number of external hard disks.