
Picas Overview¶
This page is about the PiCaS pilot framework:
About PiCaS¶
Let’s say that you have a number of tasks to be processed on the Grid Worker Nodes. Each task requires a set of parameters to run. The parameters of each task (run id, input files, etc) construct an individual piece of work, called token, which is just a description - not the task itself.
The central repository for the tasks is PiCaS, a Token Pool Server. The pilot jobs request the next free token for processing from PiCaS. As said, the content of the tokens is opaque to PiCaS and can be anything your application needs.
PiCaS works as a queue, providing a mechanism to step through the work one token at a time. It is also a pilot job system, indicating that the client communicates with the PiCaS server to fetch work, instead of having that work specified in a jdl (or similar) file.
The server is based on CouchDB (see CouchDB book), a NoSQL database, and the client side is written in Python.
Source Code¶
The source code of PiCaS is on Github Picas Client.
Picas server¶
On the server side we have a queue which keeps track of which tokens are available, locked or done. This allows clients to easily retrieve new pieces of work and allows also easy monitoring of the resources. As every application needs different parameters, the framework has a flexible data structure that allows users to save different types of data. Because of this, tokens can contain any kind of information about a task: (a description of) the work that needs to be done, output, logs, a progress indicator etc.
The server is a regular CouchDB server with some specific views installed. For more information on this, see the Background: CouchDB section.
Picas client¶
The PiCaS client library was created to ease communication with the CouchDB back-end. It allows users to easily upload, fetch and modify tokens. The system has been implemented as a Python Iterator, which means that the application is one large for loop that keeps on running as long as there is work to be done. The client is written in Python and uses the python couchdb module, which requires at least python version 2.6. The client library is constructed using a number of modules and classes, most important of these are:
The Actors module contains the
RunActorclass. This is the class that has to be overwritten to include the code that calls the different applications (tasks) to run.The Clients module contains a
CouchClientclass that creates a connection to CouchDB.The Iterators module contains classes responsible for working through the available tokens. The
BasicViewIteratorclass assumes that all the token information is encoded directly into the CouchDB documents.The Modifiers module is responsible for modification of the PiCaS tokens. It makes sure the tokens are modified in a uniform way.
How to use¶
The source code includes a simple example of how to use PiCaS. You’ll have to write your pilot job in Python. Using PiCaS boils down to these steps:
Extend the
RunActorclass and overwrite the necessary methods:
process_token; should be implemented and contain the code to process your task.
prepare_env; is called only once, before the first run of this pilot job. For example, this is a good place to download a database that will be used by all tasks.
prepare_run; is called before each task. For example, this is a good place to create output directories or open database connections
cleanup_run; is called after each task. For example, this is a good place to clean up anything setup inprepare_run. Note that it is not guaranteed that this code will be run. For example in the case of a failure during process_token
cleanup_env; is called only once, just before the pilot job is shutting down. For example, this is a good place to clean up anything setup duringprepare_env(remember to clean up your temporary files when you leave!). Note that it is not guaranteed that this code will run as the job can be interrupted or crash before this.Instantiate a
CouchClientInstantiate a
BasicTokenModifierInstantiate a
BasicViewIterator(and provide it theCouchClientandBasicTokenModifier)Instantiate your
RunActorsubclass (and provide it theBasicViewIteratorandBasicTokenModifier)Call the run() method of your
RunActorto start processing tokens
For another example, see the Picas Example in our documentation.
Grant access on Picas¶
Any user with a Grid project and allocated quotas can get a PiCaS account and also obtain a database on the CouchDB server. If you want access, just contact us at helpdesk@surfsara.nl to discuss your design implementation and request your PiCaS credentials.
Background: CouchDB¶
PiCaS server is based on CouchDB. CouchDB stores documents which are self-contained pieces of information. These documents support a dynamic data model, so unlike traditional databases, CouchDB allows storing and retrieving any piece of information as long as it can be defined as key-value pairs. This feature is used to store all the information needed to keep track of the job stages and all of the required in- and outputs.
CouchDB also provides a Restful HTTP API, which means that we can easily access information with an HTTP client. This can be a browser, a command-line application like curl or a complete client library. It is also possible to interact with the CouchDB database behind PiCaS using the web-interface.
Picas views¶
CouchDB views are the basic query mechanism in CouchDB and allow you to extract, transform and combine data from different documents stored in the same database. This process is based on the Map/Reduce paradigm. In the case of CouchDB, the Map step takes every document from a database and applies a piece of code. It then sorts the output of that step based on the key that you supply and give it to the reducer. The code you supply for the reducer combines data from the mapper that have the same key.
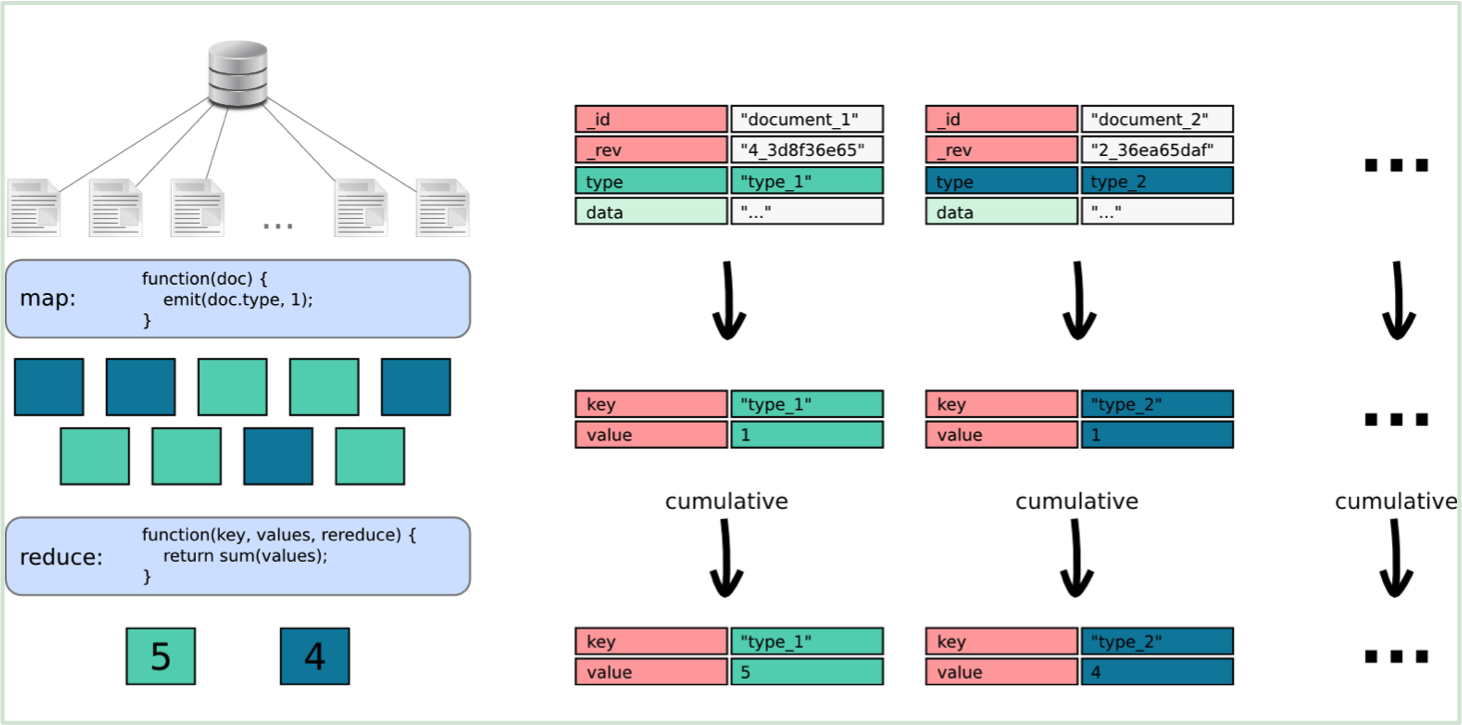
The map code works on a ‘per document’ basis, so every document is run through that code one by one. The emit statement returns the value to the reduce command, again, this is all done for every document. In this case we are only interested in the type of the document, and as we want to count how many of each type there are, we provide the type as the key for the emit statement.